
Talk to anyone in AI, analytics, or data science, and they’ll tell you synthetic data is the future. But ask them what they mean by “synthetic data,” and you’ll get wildly different answers. That’s because synthetic data isn’t just one thing—it’s a broad category with multiple use cases and definitions. And that ambiguity makes conversations confusing.
So, let’s cut through the noise. At its core, synthetic data operates along two key dimensions. The first is a spectrum ranging from filling in missing data in an existing dataset to generating entirely new datasets. The second distinguishes between interventions at the raw data level versus interventions at the insights or outcomes level.
Imagine these dimensions as axes on a chart. This creates four quadrants, each representing a different type of synthetic data: data imputation, user creation, insights modeling, and manufactured outcomes. Each one serves a distinct function, and if you’re working with data in any capacity, you need to know the difference.


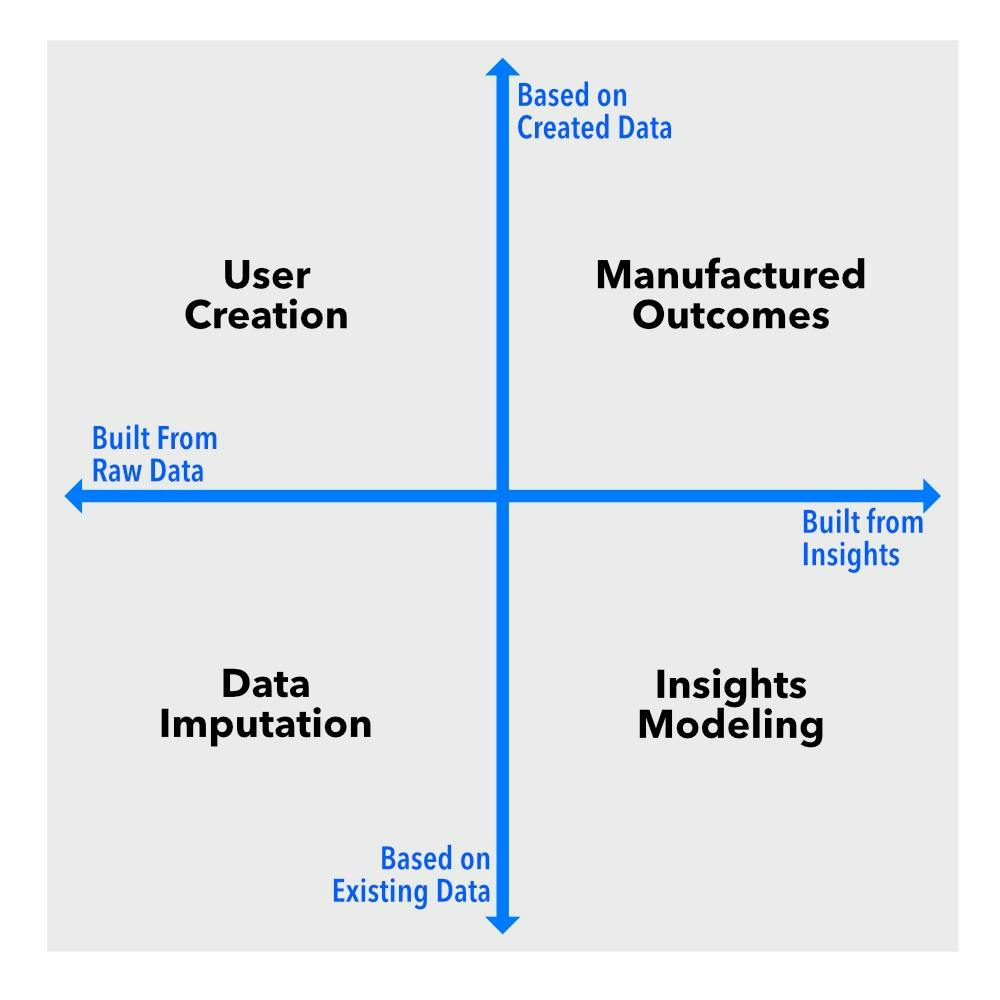
Data Imputation: Filling in the Blanks
While some might argue that data imputation isn’t truly synthetic data, modern imputation techniques have evolved beyond simple mean or median substitution. Today, advanced imputation leverages machine learning and generative AI models, making the generated values more sophisticated and contextually relevant than ever before.
Data imputation sits at the intersection of missing data and raw data intervention. This means we’re working with existing datasets that have gaps, and our goal is to generate plausible values to complete them. Unlike other types of synthetic data, imputation isn’t about creating entirely new information—it’s about making incomplete data more usable.
Example: A market research firm conducting media effectiveness studies might have gaps in its audience response data due to missing survey responses. Instead of discarding incomplete datasets, imputation techniques—such as statistical modeling or machine learning—can generate realistic estimates, ensuring analysts can still draw meaningful insights from the data.
User Creation: Fake People, Real Insights
User creation lies between new data generation and raw data intervention. Instead of modifying existing data, this approach fabricates entirely new user profiles and behaviors. It’s particularly useful when real user data isn’t available, is sensitive, or needs to be scaled artificially.
User creation is a game-changer for testing products, improving security, and training AI models.
Example: A streaming service might create synthetic user profiles to test its recommendation engine without exposing real customer data. Cybersecurity firms do the same to simulate attack scenarios and train fraud detection systems.
Insights Modeling: Patterns Without the Privacy Risks
Insights modeling operates at the intersection of existing data and intervention at the insights level. Instead of manipulating raw data points, it creates datasets that preserve the statistical properties of real-world data without exposing actual records. This makes it ideal for privacy-sensitive applications.
Insights modeling also allows researchers to scale insights from pre-existing datasets, particularly when gathering large-scale data is impractical. This is common in marketing research, where data collection can be cumbersome and costly. However, this approach requires a solid foundation of real-world training data.
Example: A market research firm conducting copy testing might use insights modeling to scale its normative database. Instead of relying solely on collected survey responses, the firm can generate synthetic insights models that extrapolate patterns from existing normative data. This allows brands to test creative performance against a broader, more predictive dataset without continuously gathering new survey responses.
Manufactured Outcomes: When the Data Doesn’t Exist Yet
Manufactured Outcomes sit at the extreme end of both new data generation and insights-level intervention. This approach involves generating entirely new datasets from scratch to simulate environments or scenarios that don’t yet exist but are essential for AI training, modeling, and simulations.
Sometimes, the data you need simply doesn’t exist—or is too expensive or dangerous to collect in the real world. That’s where Manufactured Outcomes come in. This process generates entirely new datasets, often to train AI systems in environments that are difficult to replicate.
Example: Self-driving car companies generate synthetic road scenarios—like a pedestrian suddenly jaywalking—to train their AI on rare but critical situations that might not appear often in real-world driving footage.
Risks and Considerations of Synthetic Data
While synthetic data provides powerful solutions, it isn’t without risks. Each type of synthetic data has its own challenges that can impact data quality, reliability, and ethical use. Here are some key concerns to keep in mind:
- Bias Propagation: If the underlying data used for imputation, insights modeling, or Manufactured Outcomes contains bias, those biases can be reinforced or even amplified.
- Lack of Real-World Representativeness: User creation and data manufacture may generate data that seems realistic but fails to capture the nuances of actual user behavior or market conditions.
- Overfitting and False Confidence: Insights modeling, when improperly applied, can create data that aligns too closely with the training set, leading to misleading conclusions.
- Regulatory and Ethical Concerns: Privacy laws like GDPR and CCPA still apply to synthetic data if it can be reverse-engineered to identify real individuals.
Key Questions to Ask When Evaluating Synthetic Data
To ensure synthetic data meets quality standards, consider these questions:
- What is the source of the original data? Understanding the foundation of synthetic data helps assess potential biases and limitations.
- How was the synthetic data generated? Different methods—machine learning, statistical models, or rule-based systems—impact the reliability of synthetic data.
- Does the synthetic data maintain the statistical integrity of real-world data? Ensure the generated data behaves similarly to actual data without merely duplicating it.
- Can the synthetic data be audited or validated? Reliable synthetic data should have validation mechanisms in place.
- Does it comply with regulatory and ethical guidelines? Just because data is synthetic doesn’t mean it’s exempt from privacy regulations.
- Is there a process to update the underlying data models? Synthetic data is only as good as the real-world data it is based on. Ensuring a process for continuously updating the foundational dataset prevents models from becoming outdated and misaligned with current trends.
Wrapping It Up
Synthetic data is a broad term, and if you’re working in AI, analytics, or any data-driven field, you need to be clear on what kind you’re dealing with. Are you filling in missing data (imputation), creating test users (user creation), generating anonymized patterns (insights modeling), or building brand-new datasets from scratch (manufactured outcomes)?
Each of these plays a different role in how we use and protect data, and understanding them is key to making informed decisions in the rapidly evolving world of AI and data science. So next time someone throws around the term “synthetic data,” ask them: Which kind?






